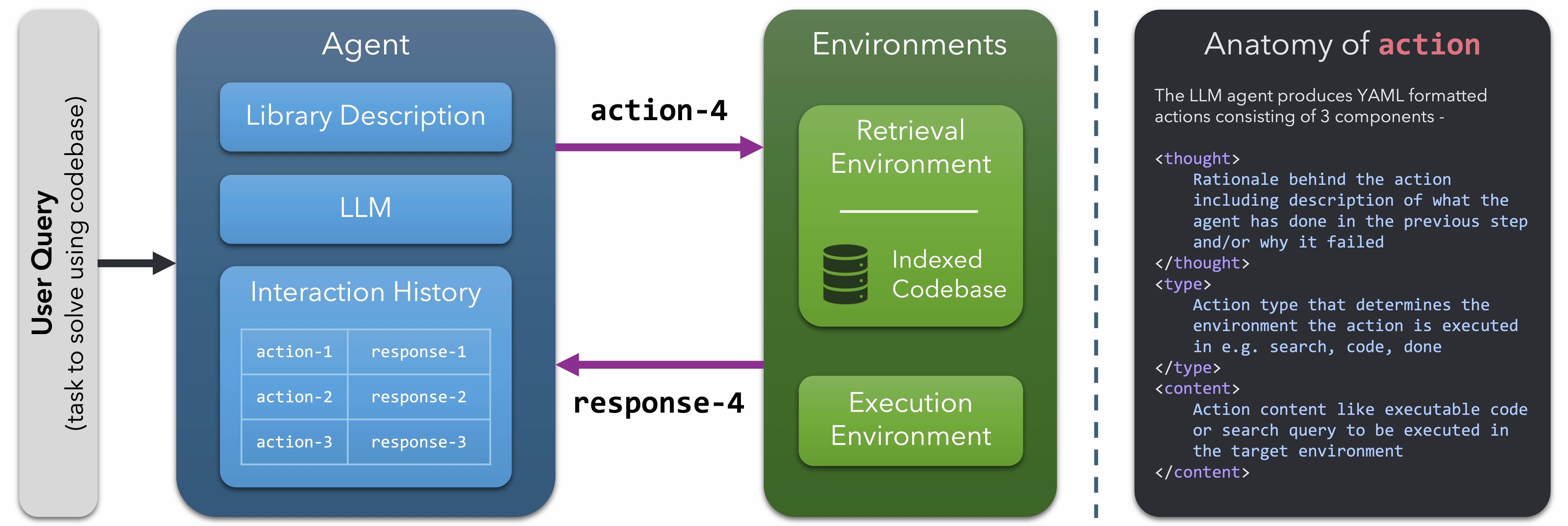



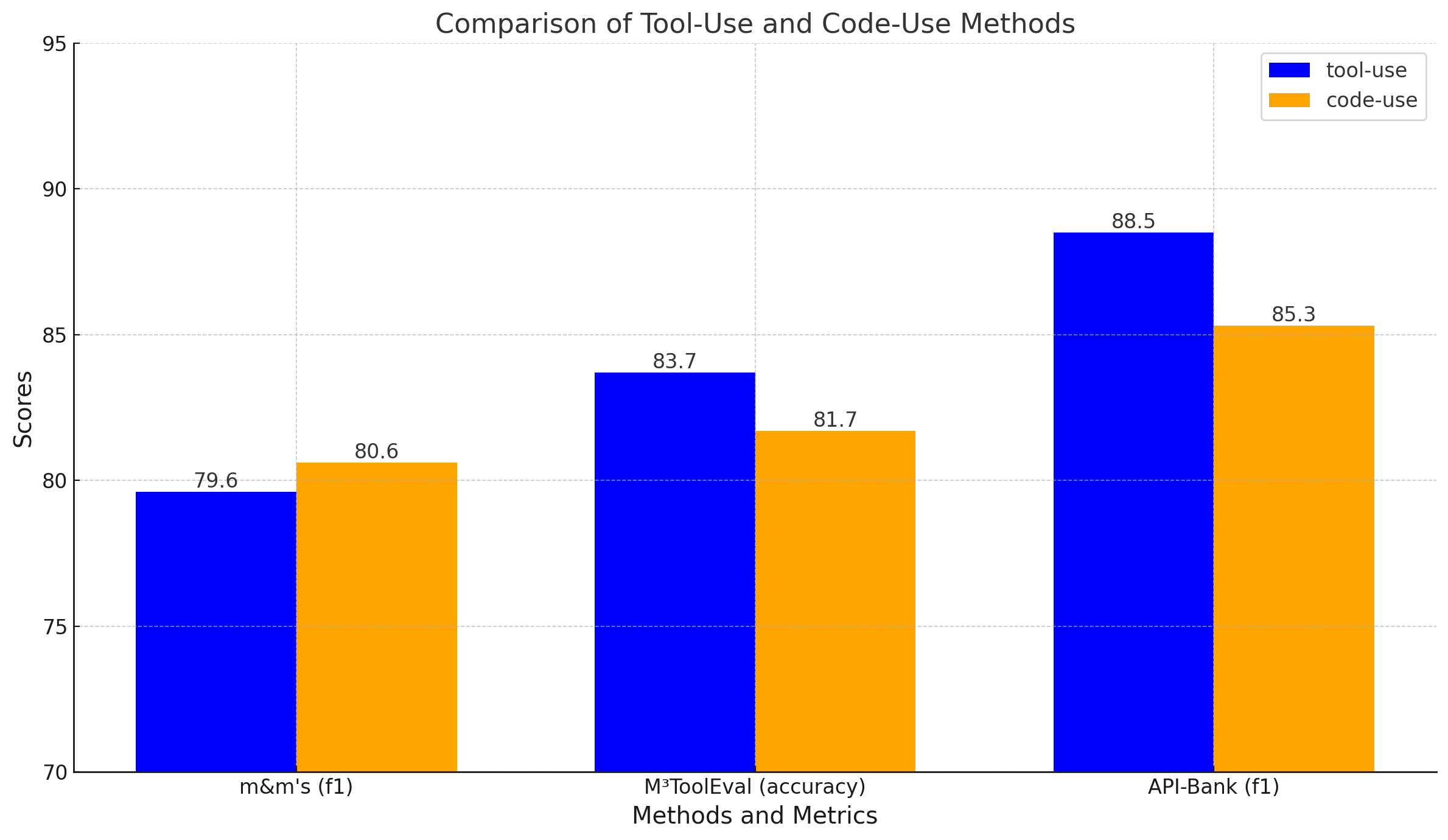
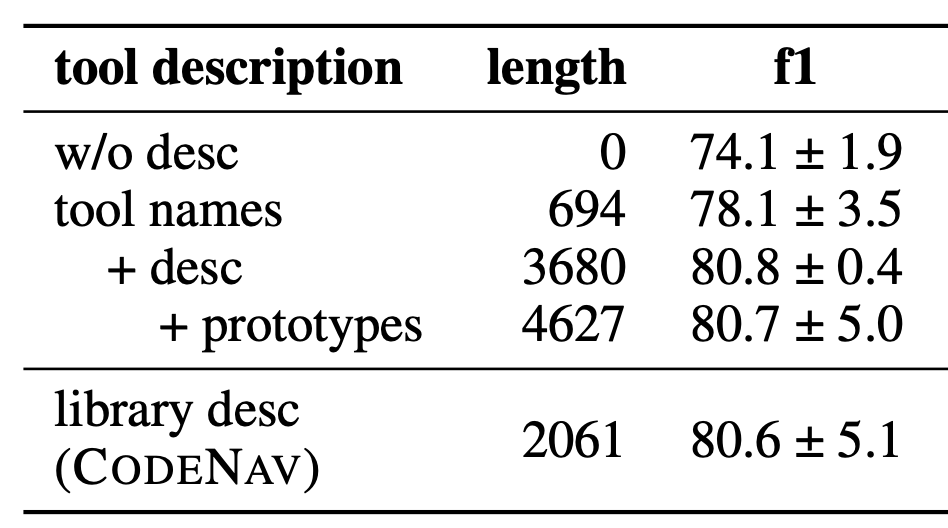
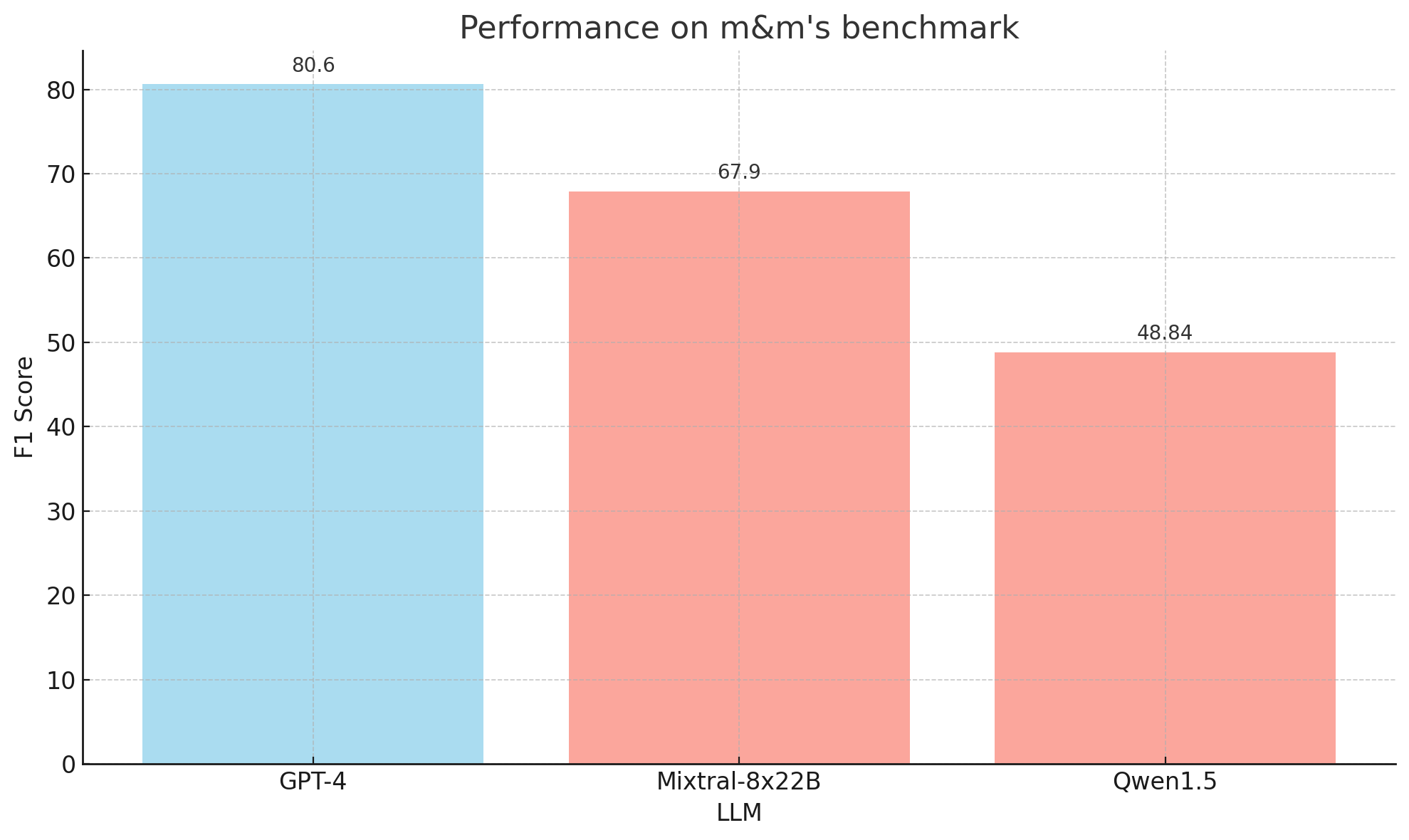
The codebase you will use is called m3eval. It has the following
directory structure:
m3eval/travel_planner.py- Function for planning travel including finding flights, making hotel reservations, and budget calculations.m3eval/browser.py- Contains theWebBrowserclass for navigating web pages.m3eval/dna_sequencer.py- Various functions related to DNA sequencing.m3eval/message_decoder.py- Functions for encoding and decoding messages, including converting hex string to ASCII and decoding Caesar cipher.m3eval/trade_calculator.py- Functions for currency conversion, calculating tariffs, etc.